/** * struct iomap_iter - Iterate through a range of a file(遍历文件的某一范围) * @inode: Set at the start of the iteration and should not change. * @pos: The current file position we are operating on. It is updated by * calls to iomap_iter(). Treat as read-only in the body. * @len: The remaining length of the file segment we're operating on. * It is updated at the same time as @pos. * @processed: The number of bytes processed by the body in the most recent * iteration, or a negative errno. 0 causes the iteration to stop. * @flags: Zero or more of the iomap_begin flags above. * @iomap: Map describing the I/O iteration * @srcmap: Source map for COW operations */ structiomap_iter { structinode *inode; loff_t pos; u64 len; s64 processed; unsigned flags; structiomapiomap; structiomapsrcmap; void *private; };
/** * dax_direct_access() - translate a device pgoff to an absolute pfn * @dax_dev: a dax_device instance representing the logical memory range * @pgoff: offset in pages from the start of the device to translate 从设备开始翻译,以页为单位的偏移量 * @nr_pages: number of consecutive pages caller can handle relative to @pfn * @mode: indicator on normal access or recovery write * @kaddr: output parameter that returns a virtual address mapping of pfn * @pfn: output parameter that returns an absolute pfn translation of @pgoff * * Return: negative errno if an error occurs, otherwise the number of * pages accessible at the device relative @pgoff. */ longdax_direct_access(struct dax_device *dax_dev, pgoff_t pgoff, long nr_pages, enum dax_access_mode mode, void **kaddr, pfn_t *pfn) { long avail;
structdax_operations { /* * direct_access: translate a device-relative * logical-page-offset into an absolute physical pfn. Return the * number of pages available for DAX at that pfn. */ long (*direct_access)(struct dax_device *, pgoff_t, long, enum dax_access_mode, void **, pfn_t *); /* * Validate whether this device is usable as an fsdax backing * device. */ bool (*dax_supported)(struct dax_device *, struct block_device *, int, sector_t, sector_t); /* zero_page_range: required operation. Zero page range */ int (*zero_page_range)(struct dax_device *, pgoff_t, size_t); /* * recovery_write: recover a poisoned range by DAX device driver * capable of clearing poison. */ size_t (*recovery_write)(struct dax_device *dax_dev, pgoff_t pgoff, void *addr, size_t bytes, struct iov_iter *iter); };
/* see "strong" declaration in tools/testing/nvdimm/pmem-dax.c */ __weak long __pmem_direct_access(struct pmem_device *pmem, pgoff_t pgoff, long nr_pages, enum dax_access_mode mode, void **kaddr, pfn_t *pfn) { /* pgoff 是在设备起始地址开始的页偏移量 */ resource_size_t offset = PFN_PHYS(pgoff) + pmem->data_offset; sector_t sector = PFN_PHYS(pgoff) >> SECTOR_SHIFT; unsignedint num = PFN_PHYS(nr_pages) >> SECTOR_SHIFT; structbadblocks *bb = &pmem->bb; sector_t first_bad; int num_bad;
if (kaddr) *kaddr = pmem->virt_addr + offset; //填充 pmem 对应的虚拟地址 if (pfn) *pfn = phys_to_pfn_t(pmem->phys_addr + offset, pmem->pfn_flags);
if (bb->count && badblocks_check(bb, sector, num, &first_bad, &num_bad)) { long actual_nr;
if (mode != DAX_RECOVERY_WRITE) return -EIO;
/* * Set the recovery stride is set to kernel page size because * the underlying driver and firmware clear poison functions * don't appear to handle large chunk(such as 2MiB) reliably. */ actual_nr = PHYS_PFN( PAGE_ALIGN((first_bad - sector) << SECTOR_SHIFT)); dev_dbg(pmem->bb.dev, "start sector(%llu), nr_pages(%ld), first_bad(%llu), actual_nr(%ld)\n", sector, nr_pages, first_bad, actual_nr); if (actual_nr) return actual_nr; return1; }
/* * If badblocks are present but not in the range, limit known good range * to the requested range. */ if (bb->count) return nr_pages; return PHYS_PFN(pmem->size - pmem->pfn_pad - offset); }
/** * kmap_atomic - Atomically map a page for temporary usage - Deprecated! * @page: Pointer to the page to be mapped * * Returns: The virtual address of the mapping * * In fact a wrapper around kmap_local_page() which also disables pagefaults * and, depending on PREEMPT_RT configuration, also CPU migration and * preemption. Therefore users should not count on the latter two side effects. * * Mappings should always be released by kunmap_atomic(). * * Do not use in new code. Use kmap_local_page() instead. * * It is used in atomic context when code wants to access the contents of a * page that might be allocated from high memory (see __GFP_HIGHMEM), for * example a page in the pagecache. The API has two functions, and they * can be used in a manner similar to the following:: * * // Find the page of interest. * struct page *page = find_get_page(mapping, offset); * * // Gain access to the contents of that page. * void *vaddr = kmap_atomic(page); * * // Do something to the contents of that page. * memset(vaddr, 0, PAGE_SIZE); * * // Unmap that page. * kunmap_atomic(vaddr); * * Note that the kunmap_atomic() call takes the result of the kmap_atomic() * call, not the argument. * * If you need to map two pages because you want to copy from one page to * another you need to keep the kmap_atomic calls strictly nested, like: * * vaddr1 = kmap_atomic(page1); * vaddr2 = kmap_atomic(page2); * * memcpy(vaddr1, vaddr2, PAGE_SIZE); * * kunmap_atomic(vaddr2); * kunmap_atomic(vaddr1); */ staticinlinevoid *kmap_atomic(struct page *page);
// peek the first 4KB of a PMEM file int fd = open("foo", O_RDONLY); // Open the target file char *buf = peek(fd, 0, 4096); // Peek its contents printf(“%s\n”, buf); // Print the contents unpeek(buf); // Unpeek the contents
peek() example2:immutability
1 2 3 4 5 6
// peek the first 4KB of a PMEM file int fd = open("foo", O_RDONLY); // Open the target file char *buf = peek(fd, 0, 4096); // Peek its contents printf(“%s\n”, buf); // Print the contents *buf = ‘a’; // Segmentation fault! unpeek(buf); // Unpeek the contents
**peek() example3:isolation **
1 2 3 4 5 6 7 8 9
// Thread 1: peek the first 4KB of a PMEM file int fd = open("foo", O_RDONLY); char *buf = peek(fd, 0, 4096); ... ... printf(“%s\n”, buf); // print original contents! ... unpeek(buf); close(fd);
1 2 3 4 5 6 7 8 9
// Thread 2: update the peek()’ed region // of the same file int fd = open("foo", O_WRONLY); char *buf = malloc(4096); memset(buf, 0xab, 4096); write(fd, buf, 4096); // copy-on-write to ... // a new 4KB free(buf) close(fd);
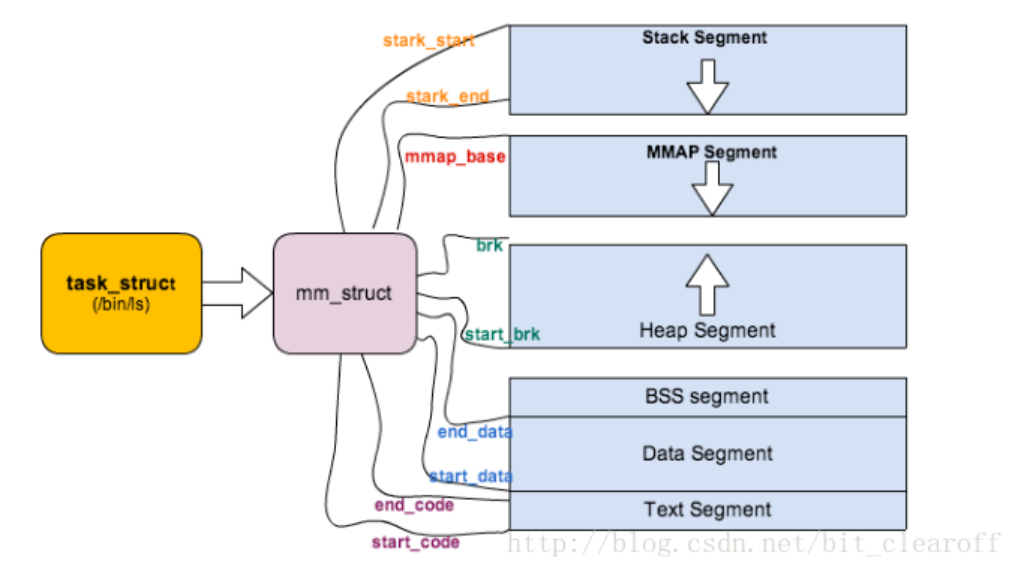
/* 在进程地址空间中搜索有效线性地址区间的方法 */ unsignedlong(*get_unmapped_area)(struct file *filp, unsignedlong addr, unsignedlong len, unsignedlong pgoff, unsignedlong flags); unsignedlong mmap_base; /* base of mmap area */ unsignedlong mmap_legacy_base; /* base of mmap area in bottom-up allocations */ /* Base adresses for compatible mmap() */ unsignedlong mmap_compat_base; unsignedlong mmap_compat_legacy_base;
unsignedlong task_size; /* size of task vm space 用户虚拟地址空间的长度 */ unsignedlong highest_vm_end; /* highest vma end address */ pgd_t * pgd; /* 指向进程页表起始地址 */ atomic_t mm_users; /* 共享同一个用户虚拟地址空间的进程的数量 */
ENTRY(stext) bl preserve_boot_args bl el2_setup // Drop to EL1, w0=cpu_boot_mode adrp x23, __PHYS_OFFSET and x23, x23, MIN_KIMG_ALIGN - 1 // KASLR offset, defaults to 0 bl set_cpu_boot_mode_flag bl __create_page_tables /* * The following calls CPU setup code, see arch/arm64/mm/proc.S for * details. * On return, the CPU will be ready for the MMU to be turned on and * the TCR will have been set. */ bl __cpu_setup // initialise processor b __primary_switch ENDPROC(stext)